
python爬虫的基本运用,利用获取网页内容、解析、正则表达式即可抓取大部分简单的网络数据

工具库
- request – 网络请求
- BeautifulSoup – 标签解析
- re – 正则表达式
操作示例
一、基本技能
抓取网页内容的基本技能就是会使用浏览器的开发者工具,此处使用的是Chrome,打开开发者工具,点击抓取网页标签,鼠标移动到想获取的标签内容,即可显示出当前部分html和class的标签
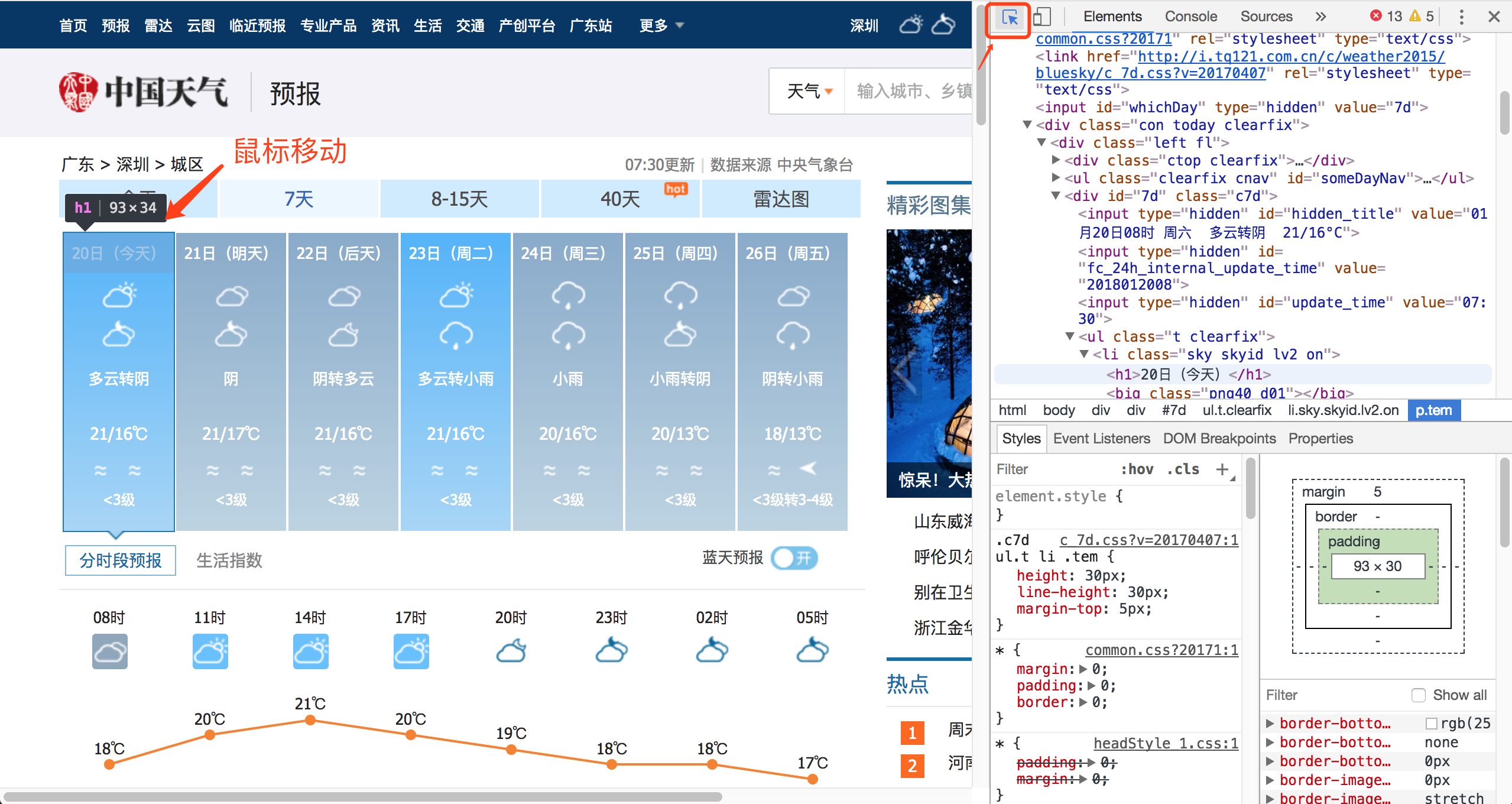
二、抓取简单的网页数据
- 此处以中国天气网为例进行抓取一周的白天和夜晚的温度
1.获取网页所有源码内容
1 | # 设置请求头 |
2.查看所需内容的标签
- 由于我们需要抓取温度,则打开开发者模式,点击抓取,将鼠标放置温度处,即可获取到网页内容对应的标签
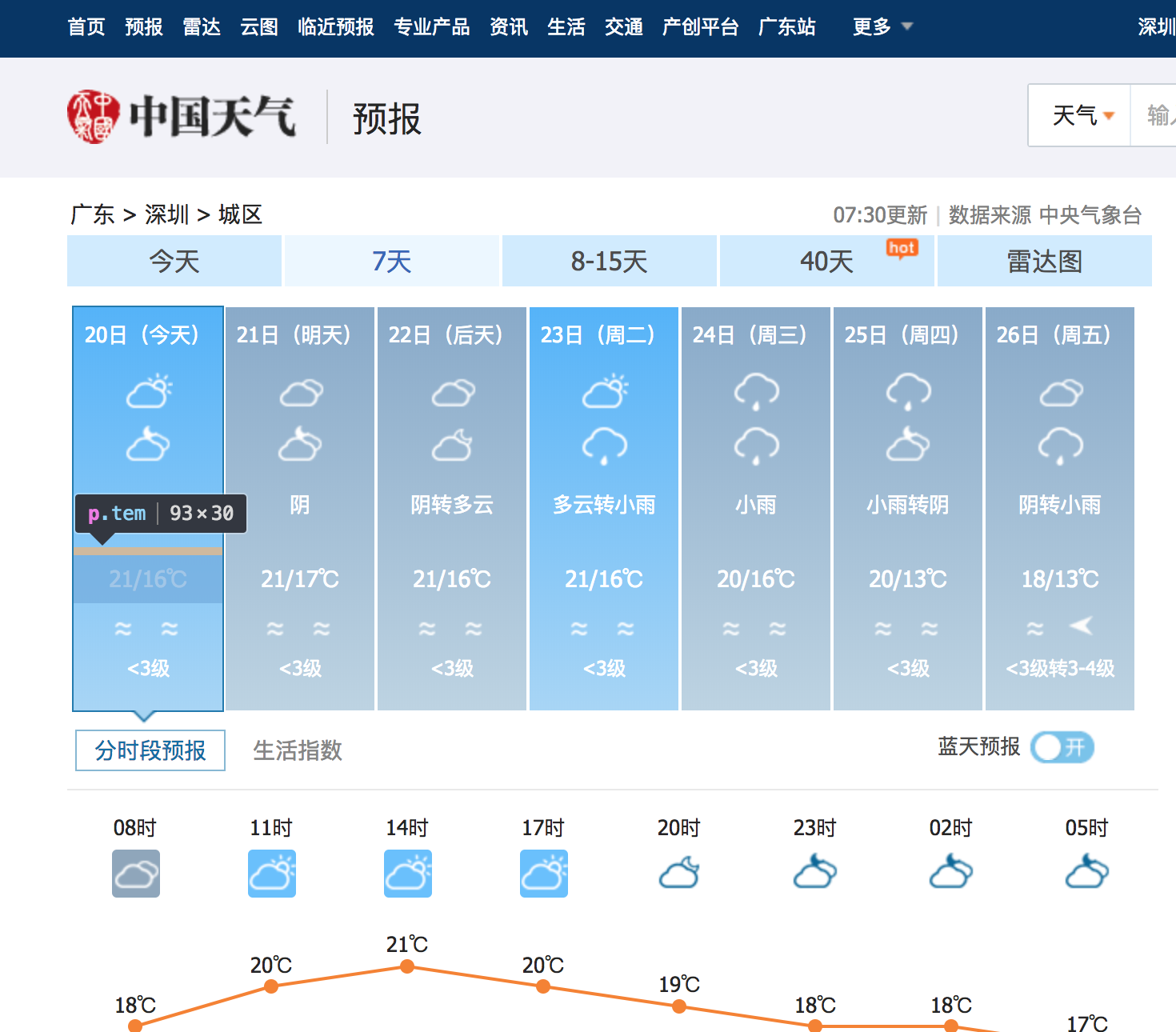
3.利用BeautifulSoup解析标签内容
1 | soup = BeautifulSoup(html.text, "lxml") |
- get_text()代表抓取去除标签后的内容
- 需注意BeautifulSoup的解析模式(当前使用的’lxml’)
- 由此即可使用requests和BeautifulSoup抓取简单的网页内容
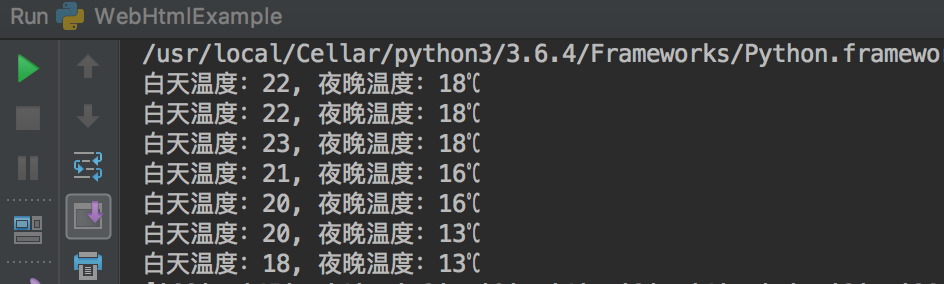
三、利用正则表达式抓取复杂的网页数据
- 此处以python3吧为对象抓取每篇帖子的回复数
1.尝试用BeautifulSoup抓取标签内容
- 浏览器开发者工具获取到回复数的标签为span.threadlist_rep_num.center_text
1 | html = requests.get("http://tieba.baidu.com/f?ie=utf-8&kw=python3", headers=headers) |
- 发现抓取到的内容为空
2.利用正则表达式解析数据
正则表达式可以快速的利用正则匹配的功能将数据抓取,此处通过浏览器找到当前标签的源码
1
<span class="threadlist_rep_num center_text" title="回复">9</span>
根据此内容写出正则匹配的语句 “(?<=”回复”>)\d*(?=)”,意为”回复”之后”\“之前任意长度的数字
- 不熟悉正则表达式的同学可以查看此文章简单学习一下
1 | html = requests.get("http://tieba.baidu.com/f?ie=utf-8&kw=python3", headers=headers) |
- 发现即可成功抓取到数据
